この記事は「N予備校プログラミングコース Advent Calendar 2022」 17 日目の記事です。
こんにちは、つまみ (@TrpFrog) です。 大学で深層学習と自然言語処理の勉強をしています。
突然ですが皆さん!ChatGPT をご存知ですか?
ChatGPT は OpenAI の開発したチャットボットです。とても賢くてすごいので、 連日ツイッターでは ChatGPT とのやりとりのスクリーンショットが流れてきます。


もし ChatGPT を初めて知ったよ! という方がいれば今すぐ OpenAI の ID を取得して ChatGPT を使ってみてください。 面倒だから登録したくないぜ……!という方も Twitter でバズっている ChatGPT 関連のツイートを見てみてください。 きっと驚くと思います。
・・・
自然言語でさまざまなやり取りのできる ChatGPT ですが、実は対話をするだけでなくコーディングもできてしまいます。例えば
と言ってみます。


適切な答えが返ってきました。
すごくないですか?
すごすぎて「プログラマの仕事がなくなってしまう……」のような意見も出てくるくらいです。
ですが!僕はそんなことは無いと思っています。 それどころか、うまく使えばコーディング速度は爆速になるし、 新しい知識も手に入るしでプログラムを書く人にとって嬉しいことばかりだと思っています。
そんなわけで今日は
- AI コード生成ツールを使うとめっちゃ捗るよ!という話
- そもそもどのようにこれらが動くのか? という話 ←たくさん書いた
- こいつらは欠点もあるから注意して使おうね という話
の 3 つについてお話しします。
それでは見ていきましょう!
免責事項
その1
サービスによっては
- 営利目的での利用を禁じていたり
- コードの著作権がアレだったり
- ちょっとグレーな部分もあったりする
かもしれないので、そこは各サービスの規約を確認して使ってください。
その2
個人の意見を書いています。所属する組織や団体の見解ではありません。
(ちょっと言ってみたかった)
AI の便利な使い方
Case 1: とりあえず補完してもらう

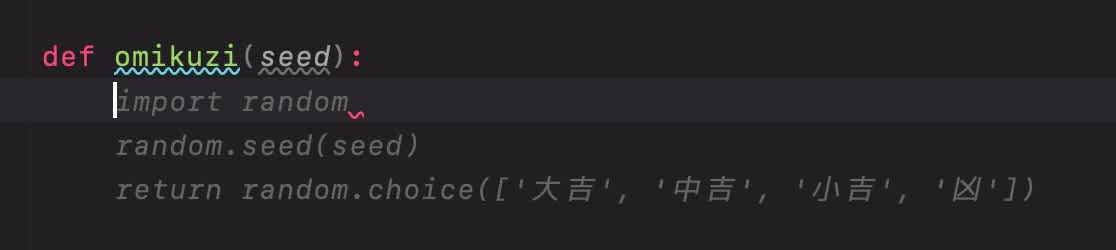
これはエディタにインストールするタイプの AI ツール (後述) 限定の機能ですが、一番よくある (というか勝手にやられる) 使い方です。
AI は賢いので我々のコードを読んでコードを提案してくれます。
画像の例では def omikuzi(seed) と書いただけで、「乱数のシードを設定してからおみくじを引く」コードを書いてくれました。
単純に我々の思考を先読みしてくるのでコーディングが爆速になります。 ただし提案してくるコードが誤っている場合があるので、必ずコードの確認はしてください。
これは AI の仕組みから考えるとなんとなく分かるのですが、奴らは雰囲気を理解しているだけでロジックについては理解していません。 (というと主張が強くて、巨大言語モデルはロジックも理解しているのでは?という意見もあったりします。) ですから、それっぽいけど間違っているコードを吐くことが大いにあります。気をつけましょう。
Case 2: ググる代わりに使う
これが一番推したい使い方です。
例えば
["1", "2", "X", "3", "4", "5", "X", "6", "7"]
という配列から "X" の間の要素だけ切り出したいとします。
しかしあなたはこの方法を知りません。こんなとき、どのように検索をしますか?
……
難しいですよね!そこで AI に質問をしてみます。ここでは ChatGPT を使ってみます。
JavaScriptconst array = ["1", "2", "X", "3", "4", "5", "X", "6", "7"]; const startIndex = array.indexOf("X"); const endIndex = array.lastIndexOf("X"); const result = array.slice(startIndex + 1, endIndex); console.log(result); // ["3", "4", "5"]


一発で目的のコードが出てきました!しかし先ほど「提案してくるコードが誤っている場合があるので、必ずコードの確認はしてください」と書きました。 ですので、ここで知った関数について JavaScript の公式ドキュメントを調べてみましょう。
- Array.prototype.indexOf() - JavaScript _ MDN
- Array.prototype.lastIndexOf() - JavaScript _ MDN
- Array.prototype.slice() - JavaScript _ MDN
これで JavaScript の配列の関数を 3 つ覚えました!普通には検索をしづらい内容でも、AI を使うことで
- コードの推論をしてもらう
- 推論されたコードから知らない関数について調べる
- 自分のスキルが上がる!(うれしい)
という流れが一瞬でできてしまいました。特にドキュメントを読んだことで、自信を持って提案されたコードを使えるようになるのは大きいです。
これは他のコード生成サービス (後述) でも使うことができます。例えば GitHub Copilot では次のような使い方ができます。


コメントに処理したい内容を書いて改行、しばらく待つと候補が出てきます。これを使えばブラウザを開かずともエディタ上で推論してもらうことができて便利です。
コーディング × AI なサービス
コーディングに役立つ AI サービスはたくさんあります。この記事では 4 つ紹介します。
Tabnine

Tabnine 社の AI コーディング支援ツールです。独自でトレーニングしたモデルを使っているみたいです。 月額 $12 ですが、無料版も存在します。(が、機械学習モデルがちょっと古いらしい?)
以前は学生無料だったはずだったのですが無くなってしまいました。残念

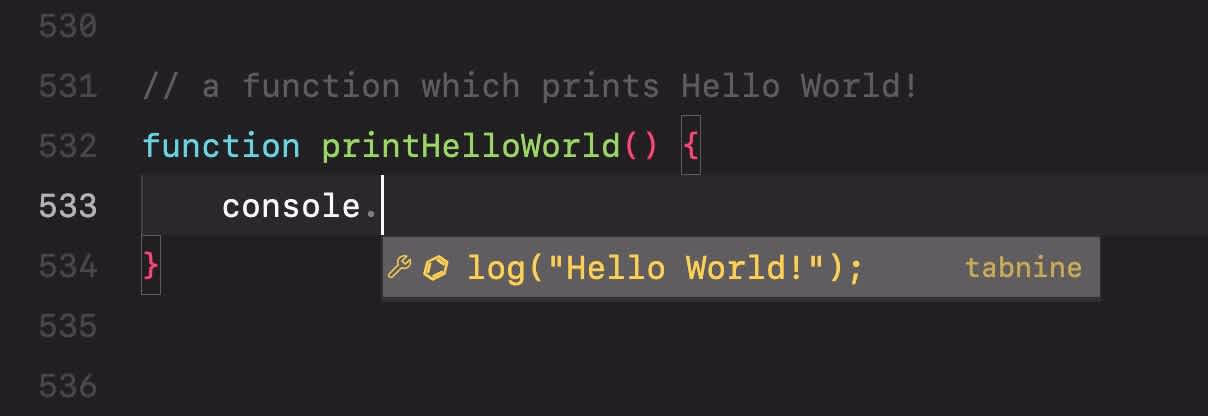
エディタにプラグインとしてインストールして使います。 入力候補がポップアップの中に出てくるので邪魔にならなくて良いです。
有料版だと Copilot (後述) のように行に介入して表示させられるみたい (未確認) ですが、僕はこっちの方が好みです。
GitHub Copilot

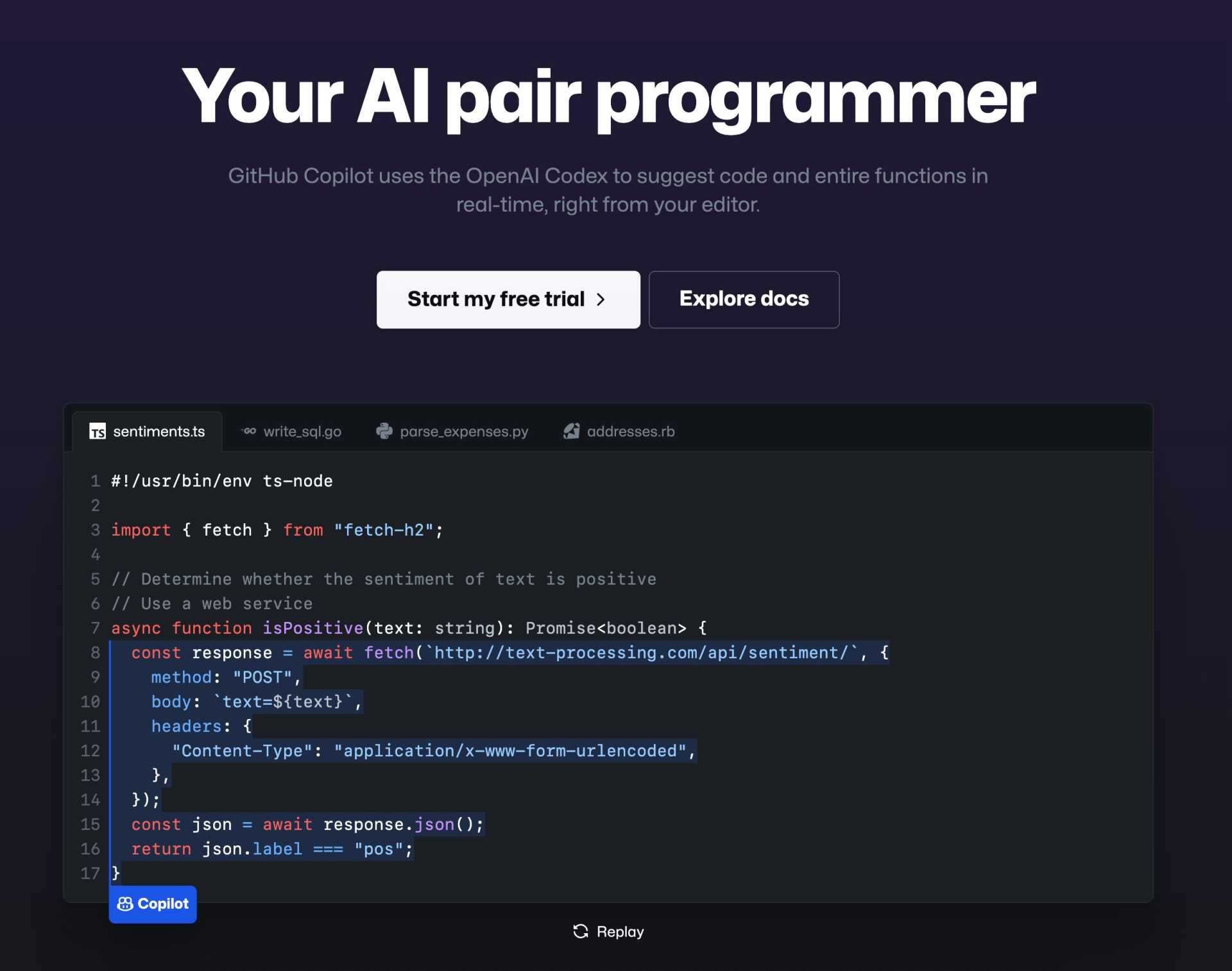
GitHub 社の AI コーディング支援ツールです。OpenAI Codex (OpenAI GPT-3 をコード生成向けに改良したもの) を使っているみたいです。 Tabnine 同様にエディタにプラグインとしてインストールして使います。
GitHub Copilot はエディタにそのまま介入してきて入力候補を提示してきます。 Ctrl + [, Ctrl + ] で別の候補を見ることもできます。
(たぶん有料版の Tabnine もできると思いますが) 長めの推論を良くしてくれるイメージがあります。 自然言語の推論もしてくれたりするので、大学のレポートが Tab キーだけで完成しそうになったこともあります。 (冗談ですよ!怖いのでちゃんと Copilot を無効にして書きました……)
月額 $10 です。学生の場合は無料の GitHub Student Developer Pack についてきます。他にも JetBrains IDE が無料で使えたりと、いろいろ特典があるので学生の人は今すぐ登録しましょう!今すぐに!
AI Programmer


こちらは Tabnine や GitHub Copilot とは異なって Web アプリケーションです。

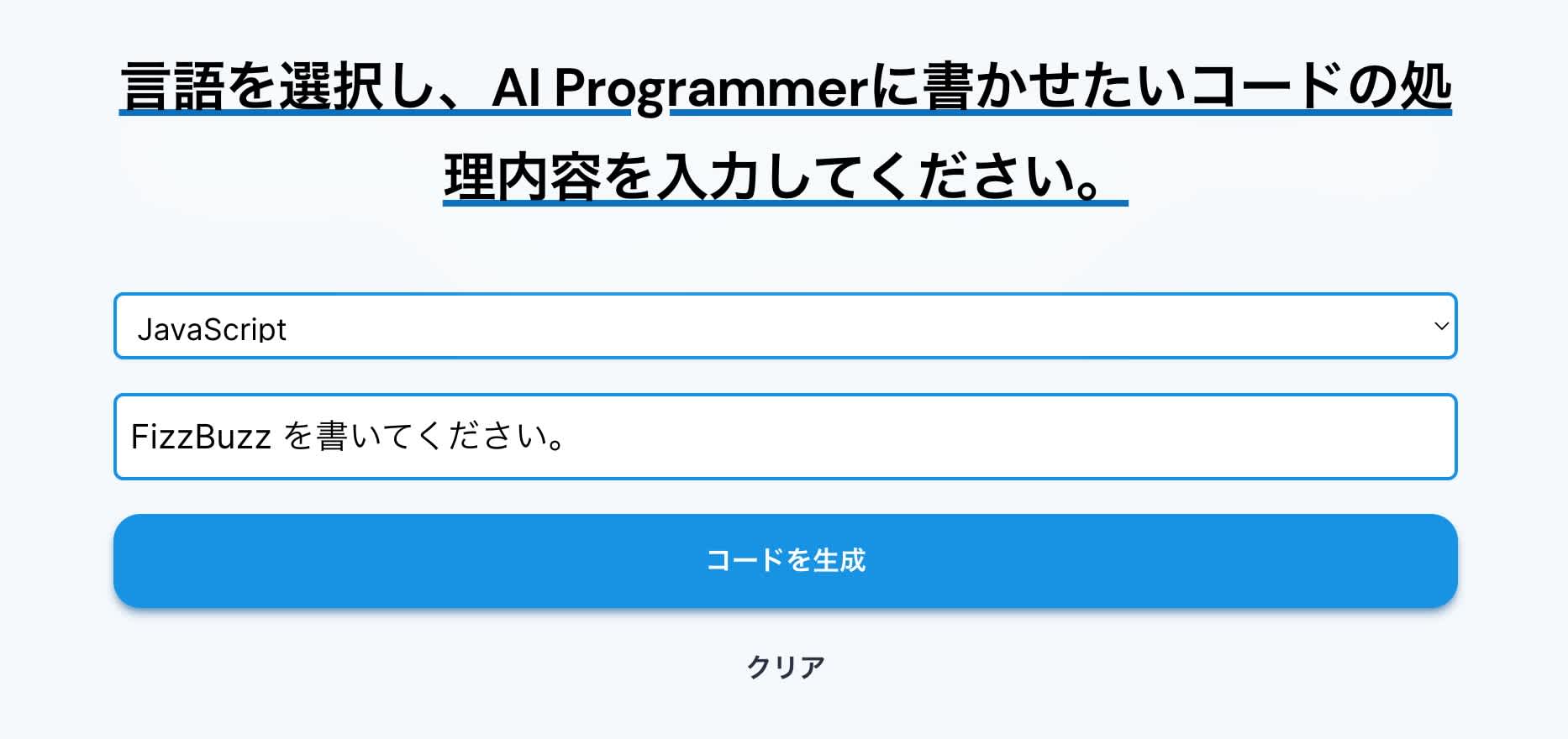
書かせたいコードの内容を説明すると、

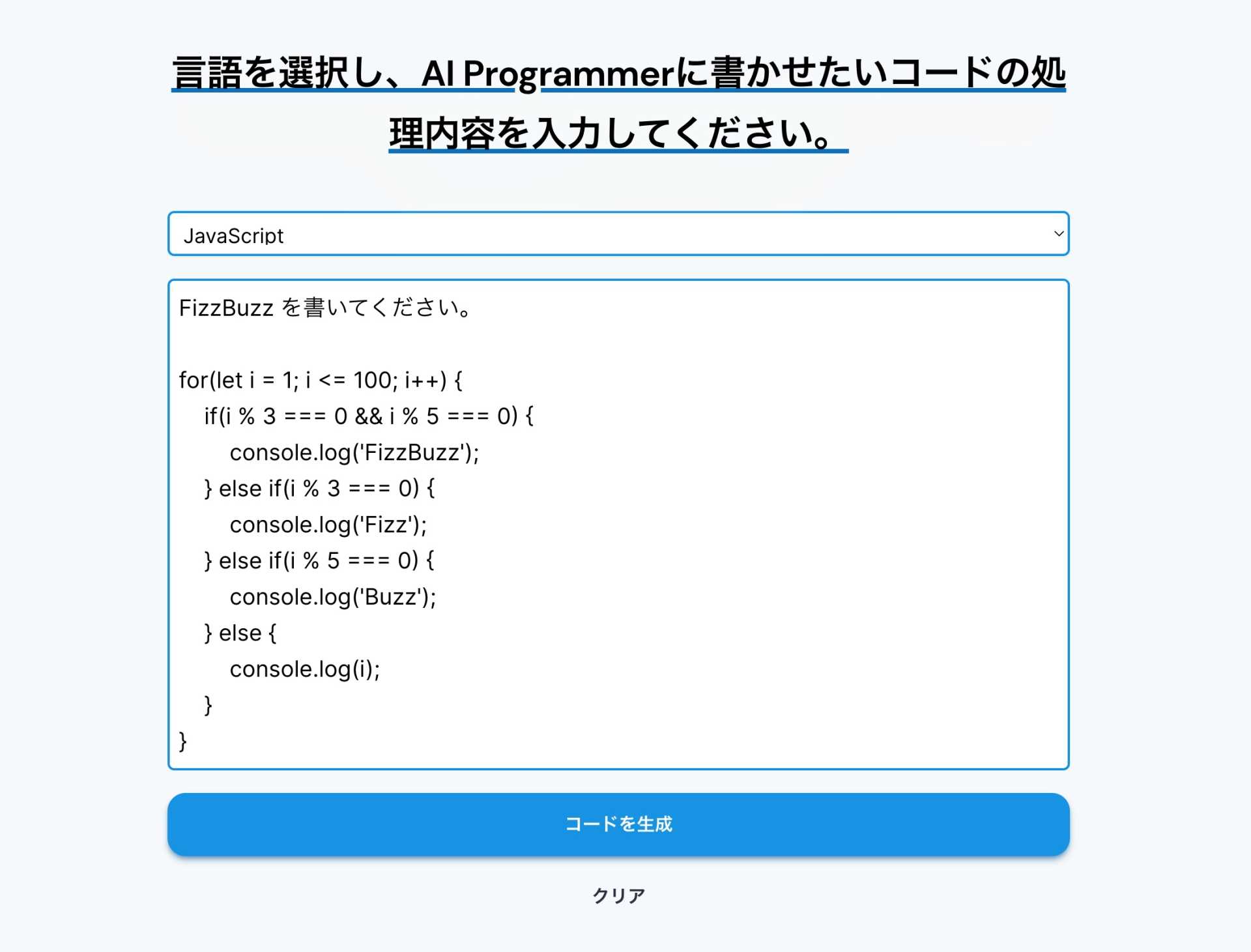
コードを書いてくれます。 実は OpenAI GPT-3 (めっちゃ強い言語モデル) のフロントエンドなので、性能はかなり良いです。
OpenAI ChatGPT


OpenAI が先日公開したばかりのチャットボットです。OpenAI はイーロン・マスクを始めとする IT の強い人たちが出資して作った研究組織です (ソース)。
中身は GPT-3 を (PPO とか使った) 強化学習で fine-tuning してより”安全” (悪口を言ったりしない) にした InstructGPT を、もうちょっと改良したモデルです。
チャットボットなので自然言語でのやり取りができます。


ChatGPT にはコーディングに関する質問をすることもできます。例えば以下のようになります。
コードを提示してくるだけでなく、内容について説明もしてくれます。便利です。
ただし、繰り返しにはなりますが、この人たちはあくまで雰囲気で回答しているだけで嘘もめちゃくちゃ言います。 プログラミング言語の機能や関数については、公式ドキュメント等で裏取りをきちんとしましょう。
そもそもなんで AI は喋れるの?
わかりません。なんで喋れるんですか?機械学習何も分からん
まず AI とは Artificial Intelligence (人工知能) の略で、知能を持つように見えるもの全般を指す言葉です。 つまり、人間っぽければルールベースだろうがなんだろうが人工知能です。
最近流行っている画像生成 AI (Stable Diffusion, Midjourney, DALL-E, Novel AI など) やチャットボットAI (ChatGPT など) は、 ほとんどがDeep Learning(ディープラーニング, 深層学習)で作られています。
Deep Learning というのは人間の脳を模倣した計算モデルであるニューラルネットワークをめちゃくちゃ深く、ディープにしたものです。 何言ってるか分からないですね
「人間の脳を模倣した」みたいな言い回しはよくされがちですが (まあそうなんだけど)、実際は
- (1) 入力をどうにか数値列 (ベクトル) に変換して
- (2) ベクトルに行列 $1$ を掛け算する
- 行列の初期値はランダム
- あとでベクトルの微分 + 逆伝播法を使って改善する (理解できなくて良いです)
- (3) ベクトルを非線形な関数に通す
- 例えば $f(x) = \max(0, x)$ とか
- 理解できなくて良いです、
僕もよく理解できていないので
- (2') ベクトルに行列 $2$ を掛け算する
- (3') ベクトルを非線形な関数に通す
- (2'') ベクトルに行列 $n - 2$ を掛け算する
- (3'') ベクトルを非線形な関数に通す
- (2''') ベクトルに行列 $n - 1$ を掛け算する
- (3''') ベクトルを非線形な関数に通す
- (2'''') ベクトルに行列 $n$ を掛け算する
- (4) 得られたベクトルになんらかの処理をして答えとする
という単純な行列計算をやっているだけです。もちろん最新の技術だともっと意味不明な演算をしていますが基本的にはこうです。 行列計算の意味が分からない方は「足し算と掛け算をしているだけ」の認識で良いです。実際ほぼ足し算と掛け算なので
とにかく何が言いたかったのかと言うと、
「AI!」「人間の脳を模倣している!」と聞くとめちゃくちゃ強そうですが、 完全なる謎技術なんかではなく、 ちゃんと人間に理解できる計算の繰り返しでできているんですよ!
ということです。AI は怖くない! 確かに「なんでこれだけであんなにうまく行っちゃうのか?」を考えると怖いのですが、それは置いといて……
AI がどのように文章を作るのか? については付録として次のページに用意してみたので、気になる人は読んでみてください。
それと N 予備校でも機械学習の勉強ができます! この記事は大学生が 1 年未満で得た知識をベースに書いているので「もっと正確な情報が知りたいよ!」という方はこちらを覗いてみてください (深層学習よりも古典的な機械学習の話がメインですが)。 また機械学習でよく使われる Python の知識や、行列に関する知識も得られて良い感じです。いい感じでした。
懸念点
とはいえ AI の言うことを鵜呑みにすると危険です。ここで 2 つの記事を紹介しておきます。
出力コードに存在する脆弱性
AI の出力は必ずしも完璧ではありません。 実際に動作するコードを出力したとしても、そのコードが脆弱性という重大な欠点を持っている可能性があります。
研究者らが脆弱性を検証:Innovative Tech - ITmedia NEWS
上記リンクの記事では GitHub Copilot の生成したコードの 4 割に脆弱性が存在したことが報告されています。
おそらく GitHub Copilot は GitHub 上のコードで学習されているために脆弱性のあるよくないコードを学習してしまったり、 学習したコードをベースにダメな応用例 (文字列に変数を埋め込むことを学習したが故に、それを応用して OS コマンドインジェクションを引き起こすようなコードを出力してしまう、など) を出力してしまったりが原因なんじゃないかな〜と思っています。(この辺はよくわかっていないので、詳しく知りたい方は論文を読んでみてください)
とにかく AI はそれっぽさを学ぶだけであり、出力の安全性などは考慮されていません。 いずれそれを考慮したような技術も登場するかもしれませんが、現状では AI の出力は不完全なので、 プログラマには脆弱性を見抜く力も必要になるのかな と思っています。
そういう意味でも、AI がまだプログラマに取って代わることはまだまだ無いんじゃないかな?と思っています。
コードの著作権
画像生成の分野でもわりと問題になっていますが、コード生成AIでも似たような著作権の議論が起こっています。
学習元のコードのライセンスがガン無視されているのでは?という声が上がっているみたいです。 AI は訓練データをうまく表現できるようにパラメータを調整していくのであるということをこの記事で書きました。 (たぶん書いた、書いてなかったらそういうことだと思ってください)
この訓練過程から考えると人間と同様に学習しており、 つぎはぎのコラージュを作っているわけではないから大丈夫なのではないかな〜と思いたいです。 ですが、やはり性能のあまり良くないAIの場合過学習の問題があり、 学習したコードをそのまま吐いてしまうこともあるので難しい問題に感じます。
まだ訴訟自体は始まったばかりですので、その辺は注視しつつ、うまく使っていければ良いかな〜と思います。 あとヤバそうな出力は使わないとか(難しい)、出力を書き方の参考にする程度に留めておくとか、いろいろできるかと思います。
まとめ
AI について「シンギュラリティが来る!」とか「エンジニアの仕事がなくなる!」とかといろいろ騒がれていますが、まあ当面はそこまで心配しなくても良いかな……と思っています。というのも、やっぱり AI はまだまだ不完全な技術だからです。脆弱性のあるコードは出力するし、平然と嘘をつくこともあります。
個人的には AI を過度に恐れたり、過度に信用したりするのではなく、「めっちゃ技術に強い友達」程度に考えればうまく付き合っていけるのでは?と思っています。 「めっちゃ強いけど、まあこいつたまに嘘つくし、一応鵜呑みにせず裏取りしてから使うか……」程度の気持ちでうまく利用してやるのです。
というスタンスでうまく AI と仲良くコードを書きたいな〜と思っています! コーディング速度は爆速になるし、新しい知識も手に入るし……AI くんいつもありがとう〜
皆さんも AI を仲良くしてくれると嬉しいです!良いコーディングライフを!
以上、つまみ (@TrpFrog) でした。さようなら